生成式 AI 產品最核心的當然就是 LLM 模型了,大部分企業自己架設 GenAI 產品主要是考量資安問題、以及針對使用場景 fine-tune 模型,因此對於模型的基本認識是非常重要的,尤其近日在 debug 的過程中更有所體悟,故前幾日會由淺到深,主要著重在開發過程中會需要了解的部分,我們先從模型的架構拆解開始。
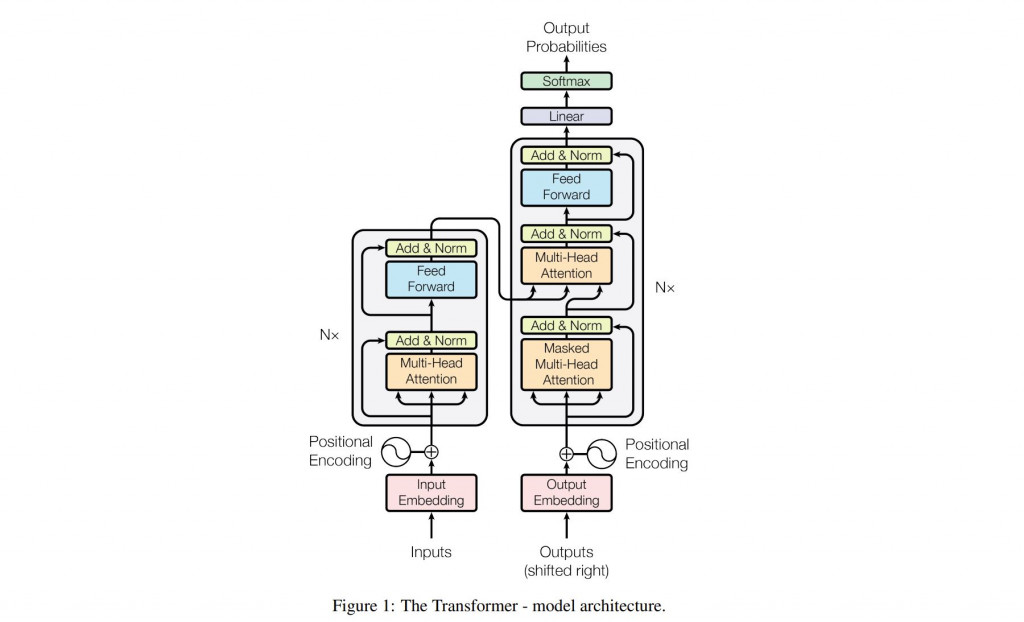
附上一張一定非常多人看過的 Transformer 架構圖,源自2017年發表的一篇非常著名的論文《Attention is All You Need》,這篇論文原本是 Google 為了優化翻譯工具而做的研究,但在後來被 OpenAI 等公司廣泛應用,如今市面上大多數的 LLM(大型語言模型)都是基於這個架構訓練出來的。
Transformer 架構的基本運作是通過 編碼器(Encoder) 和 解碼器(Decoder) 兩個核心部分來實現的。編碼器像一個專注於理解輸入內容的讀者,負責處理並理解輸入的數據,並轉換成一系列特徵向量。接著這些特徵向量會被傳遞給解碼器,而解碼器就像是一位作家,它根據編碼器理解的內容,生成新的序列,比如翻譯後的句子或其他文本。
而 Transformer 架構又可以衍生出三種主要類型的模型:
在編碼器和解碼器之間,有一個關鍵的運作機制叫做自注意力機制(Self-Attention)。這個機制能夠逐步分析輸入數據中的每個部分(如句子中的每個詞彙)與其他部分之間的關係。通過這種方式,模型可以識別哪些詞對當前詞的理解最為重要,進而更精確地捕捉上下文信息。這種處理方式使模型在理解輸入文本時能夠更全面,並在生成文本時更連貫和自然。
具體的運作機制可以參考附錄的文獻與課程介紹。
我們可以透過 Huggingface 的 pipeline 套件一窺 transformer 能為我們執行那些任務,這個套件包裝將整個文字從輸入到輸出的整個過程,我們用這個套件示範三種不同 transformer 架構的模型:
bert-base 的 model。from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
data = "We are SI Dream Engineering Team."
sentiment_pipeline(data)
No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
[{'label': 'POSITIVE', 'score': 0.9978912472724915}]
gpt-base 模型時,原本的分類任務會改成接續句子生成文字。from transformers import pipeline
pipeline = pipeline(model="openai-community/gpt2")
data = "We are SI Dream Engineering Team."
pipeline(data)
[{'generated_text': 'We are SI Dream Engineering Team. We think about doing things our own way. We want to make a good game for YOU. We will always try, and we will try, every day to do that."\n\n"You are one of the'}]
bart-base model,並把pipeline 第一段的介紹餵給模型,原本的任務就會改成摘要任務。from transformers import pipeline
pipeline = pipeline(model="sshleifer/distilbart-cnn-12-6")
pipeline(data, min_length=5, max_length=30)
[{'summary_text': ' The pipelines are objects that abstract most of the complex code from the library . They offer a simple API dedicated to several tasks, including Named'}]
ref.


 iThome鐵人賽
iThome鐵人賽